Este é um relatório de Prática como Componente Curricular entregue ao Curso de Letras-Inglês da UFJ no 2º semestre do ano de 2021.
Discente: Gabriel Lima de Souza
Professor Orientador: Márcio Issamu Yamamoto
Sumário
1. Introdução
2. Referencial teórico
3. Metodologia
3.1. Compilação do corpus em PT e em EN
3.2. ICVoTec e preenchimento de fichas terminológicas
4. Resultados
5. Considerações finais
6. Referências
1. Introdução
O Senhor dos Anéis é uma obra de fantasia escrita pelo britânico John Ronald Reuel Tolkien. O livro já vendeu milhares de cópias e foi traduzido para pelo menos 38 línguas, sucesso que gerou várias adaptações da obra, das quais a mais famosa foi a trilogia de filmes dirigidos por Peter Jackson. Esta adaptação cinematográfica ganhou vários prêmios, sendo um sucesso instantâneo. Mesmo após tantos anos desde o lançamento original, a obra de J. R. R. Tolkien continua a ser relevante e a sua adaptação mais recente é a série produzida pela Amazon Studios que será lançada neste ano de 2022.
A história do livro se passa na Terra Média, que representa a terra num passado muito distante, onde o senhor das trevas Sauron tenta recuperar o Um Anel, um anel de poder que controla os outros anéis que estão em posse dos homens, dos anões e dos elfos, e se Sauron conseguir a posse desse anel ele irá conquistar a Terra Média.
No aniversário de 111 anos de Bilbo Baggins ele decide sair do Condado (uma região habitada por Hobbits), e deixa o Um Anel com Frodo, seu sobrinho, que depois descobre a origem do anel quando Gandalf suspeita que ele pode ser um dos anéis de poder. Depois da descoberta da importância desse anel Gandalf instrui Frodo a levar o anel para longe do Condado.
Frodo, acompanhado por Sam, Pippin, Merry e vários outros companheiros que vão conhecendo durante o caminho, começam uma jornada para destruir o Um Anel, para que não caia nas mãos de Sauron.
O livro O Senhor dos Anéis foi escolhido como objeto de estudo por causa da sua influência e relevância no gênero fantasia, possuindo um mundo ficcional bastante complexo, com línguas, músicas, raças e culturas próprias, tendo esses aspectos servido como inspiração para várias outras obras. Essas características são interessantes para cumprir nossos objetivos com essa Prática como Componente Curricular, doravante PCC, que é identificar e definir a Terminologia de J. R. R. Tolkien presente na trilogia em inglês e português (bilíngue).
A Linguística de Corpus é uma metodologia de estudo da língua (dados autênticos) com o uso da tecnologia, na qual o computador é ferramenta essencial para analisar uma grande quantidade de dados e, assim, obter um resultado mais completo e confiável do que com outros métodos. Até os anos 60 e 70, a LC ficou ofuscada pela não existência de computadores pessoais e também pelo Gerativismo de Chomsky, que privilegia o aspecto imanentista da língua em detrimento ao aspecto descritivo. Com a invenção dos computadores pessoais, as análises linguísticas se tornaram mais palpáveis e factíveis (McEnery; Hardie, 2012).
Os dados do LOTR foram carregados e organizados na plataforma ICVoTec, que é uma plataforma com um banco de dados no qual os resultados como os exemplos e as definições dos termos estão disponíveis para o público.
2. Referencial teórico
A fundamentação teórica deste projeto foi baseada na metodologia da Linguística de Corpus, doravante LC; nas bases teóricas da Etnoterminologia de Barbosa (2009) e na administração dos dados terminológicos de Fromm (2011).
A definição da LC segundo Shepherd (2009, p. 153) é: “A abordagem baseada em corpus é na realidade uma metodologia que se aproveita do corpus essencialmente para testar e exemplificar teorias e descrições linguísticas pré-existentes. Através dessa abordagem, o corpus pode ser usado como fonte de exemplos, que são quantificáveis em sua frequência e extensão.”, deixando assim clara a escolha do uso da LC como abordagem e parte da metodologia nesta PCC. No contexto da LC, podemos definir corpus como uma coletânea de textos em linguagem natural, digitalizados e armazenados de forma organizada utilizado para pesquisas linguísticas. Contudo, o conceito de corpus já existia antes da LC, sendo ele coletado à mão inicialmente. Atualmente, a LC utiliza o computador para analisar dados, assim diminuindo o tempo gasto e produzindo um resultado mais confiável do que se fosse feito à mão. Uma boa metáfora para a LC é que ela está para a Linguística assim como o microscópio está para a Biologia.
Na Etnoterminologia de Barbosa (2009), a terminologia está ligada ao fantástico, como a concepção de personagens e características que existem apenas nesses mundos, como por exemplo: monstros, elfos e um anel de poder. Neste contexto, a terminologia se constitui por meio de traços semânticos que definem um ser, um objeto ou um fenômeno dentro de um universo de ficção específico. Neste trabalho, nosso foco foi estudar o universo criado por J. R. R. Tolkien e a terminologia para criação de personagens e a trama do Um Anel.
A administração dos dados terminológicos na metodologia proposta por Fromm (2011) e pela utilização do programa de análise lexical WordSmith Tools 7.0 (SCOTT, 2016) e suas ferramentas: Wordlist, Keywords e Concordance. Com a ferramenta Wordlist fizemos uma listagem das palavras únicas em relação ao total de palavras do corpus estudado. A ferramenta Keywords foi utilizada para fazer uma análise da lista de palavras do corpus estudado com um corpus de referência, com o resultado dessa análise tivemos os candidatos a termos do corpus estudado. Selecionando um dos candidatos a termo com a ferramenta Concordance, nos foi disponibilizado uma lista com esse candidato em seu contexto no corpus, possibilitando coletar suas características semânticas, gerando material para a definição dele. Com os termos levantados e verificando se é possível oferecer uma definição em português (PT) e em inglês (EN), foi cadastrado no banco de dados ICVoTec. Começamos inserindo as linhas de concordância escolhidas como exemplo de uso, depois a partir do contexto preenchemos os campos disponíveis, também preenchendo as características morfológicas e semânticas, com a inserção de vários dados. O último passo foi criar uma definição prévia para o termo, que será transformada em uma definição final.
3. Metodologia
NNesta seção, apresentaremos os passos seguidos para compilar o corpus e o preenchimento das fichas terminológicas, desde como preparar os arquivos de texto para a utilização do WordSmith e como inserir os dados coletados na plataforma ICVoTec.
3.1. Compilação do corpus em PT e em EN
Os livros foram encontrados na internet em formato pdf e, para utilizar o programa de análise lexical – WordSmith -, eles foram convertidos para o formato txt. A conversão de arquivos foi feita pelo site: https://convertio.co/pt/pdf-txt/. Apesar de ter sido muito útil a existência desse tipo de conversão, ela ainda não é perfeita e deixou o texto com caracteres a mais que precisaram ser removidos manualmente para o funcionamento correto do programa WordSmith.
Figura 1 Recorte da obra O Senhor dos Anéis em inglês em formato .txt (visão parcial).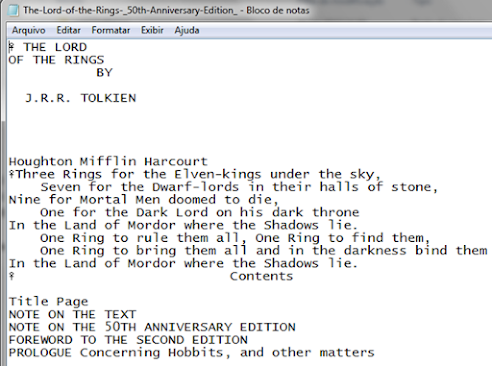
Fonte: o autor.
Os textos foram limpos retirando os caracteres a mais, os prefácios, os índices, os posfácios e deixando os livros em inglês e em português com o mesmo início e o mesmo final. Com os textos limpos e em formato .txt, agora podemos processá-los utilizando o programa WST.
Figura 2 Tela inicial do WST 7.0.
Fonte: o autor.
Com o programa aberto, selecionamos a opção wordlist para criar uma lista de palavras; com a nova janela aberta, clicamos em file e depois em new; então, selecionamos o arquivo txt que tínhamos preparado clicando na opção Choose Texts Now e depois em Make a Word List Now.
Figura 3 Tela do WST, Lista de palavras- choose your text.
Fonte: o autor.
O programa vai processar o arquivo e nos dar a nossa lista de palavras.
Figura 4 Visão parcial da Lista de Palavras do GOT em inglês.
Fonte: o autor.
Agora com a lista de palavras em mãos, vamos até a tela inicial do WordSmith e selecionamos a opção KeyWords para que possamos identificar as palavras chaves, na nova janela que abriu. Para tal, clicamos em file e depois new, selecionamos a lista de palavras que acabamos de fazer e um corpus de referência. O corpus de referência utilizado em inglês foi proveniente do COCA com 100 mil palavras e em português foi o do Banco do Português com 1, 7 milhão de palavras. Em seguida, selecionados os arquivos, clicamos em Make a Keyword List Now.
Figura 5 WST, painel inicial da ferramenta Keywords.
Fonte: o autor.
Depois que o programa processar os arquivos ele nos dará uma lista com as possíveis palavras-chave.
Figura 6 Visão parcial da lista de palavras-chaves do LOTR.
Fonte: o autor.
Começamos a excluir os itens dessa lista que não podem ser termos, como os nomes de pessoas, locais, verbos, preposições, deixando assim só os candidatos a termos na lista.
Figura 7 Lista de palavras-chave limpa.
Fonte: o autor.
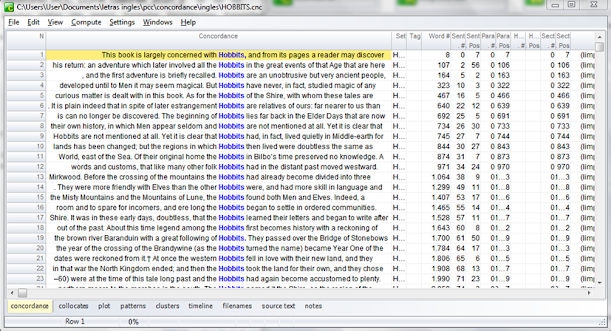
Com os candidatos a termos, podemos utilizar a ferramenta Concord, com a qual poderemos ver onde aquele candidato a termo aparece no texto e, assim, identificar se é ou não um termo. Selecionando um candidato a termo, e depois clicando em Compute e em Concordance, utilizando essa ferramenta podemos observar o candidato a termo no texto e os contextos que ele é utilizado, assim possibilitando a nossa análise.
Figura 8 Concordance - linhas de concordância para o termo hobbits.
Fonte: o autor.
3.2. ICVoTec e preenchimento de fichas terminológicas
O ICVoTec é uma plataforma terminográfica de acesso livre, utilizada para armazenamento e administração de dados terminológicos. Como produto final, o ICVotec disponibiliza os termos para o público de forma gratuita.
Começamos acessando a página inicial do ICVoTec pelo endereço:
http://ic.votec.ileel.ufu.br/ a partir de um login foi criado pelo administrador da página para que nós pudéssemos adicionar novos termos.
Figura 9 Página inicial para cadastro dos termos - acesso restrito ao pesquisador.
Depois de ter feito o login, podemos começar adicionando um novo termo clicando no botão “novo termo”.
Figura 10 ICVotec - painel de termos cadastrados.
Nessa página colocamos o termo que estamos adicionando e também selecionamos a língua dele, depois selecionamos a grande área como “terminologia em ficção" e a subárea como “o senhor dos anéis”.
Figura 11 ICVotec - cadastro do termo, língua e ontologia.
Agora preenchemos os dados do contexto, com o exemplo sendo uma parte do livro (um excerto) na qual o termo é utilizado, o conceito sendo o significado do exemplo ou o que ele diz sobre o termo, podendo ser mais de um conceito para cada exemplo em algumas situações, a fonte o nosso livro neste caso, e a data de coleta.
Figura 12 ICVotec - cadastro dos contextos.
Depois de inseridos os contextos, clicamos em “próximo passo” e inserimos os dados do termo como categoria gramatical, número, gênero e variações morfossintáticas; inserimos também os dados do corpus como posição na ordem de frequência e número de ocorrências do termo.
Figura 13 ICVotec - preenchimento das fichas terminológicas.
Em traços distintivos, colocamos os conceitos que selecionamos anteriormente, para organizar e facilitar a elaboração da definição do termo. As linhas representam os contextos e, se um conceito é equivalente ao outro conceito, eles ficam na mesma coluna, senão eles ficam em colunas diferentes. Quando uma coluna possui conceitos recorrentes, isso significa que essa característica é mais importante.
Figura 14 ICVotec - cadastro dos traços distintivos.
No campo Semântica inserimos uma definição dicionarizada do termo, caso exista, e se essa definição é coincidente com a nossa. Também inserimos hiperônimos, hipônimos, co-hipônimos, sinônimos e antônimos que o termo possui.
Figura 15 Inserção de modelo de definição proveniente de dicionário e similares.
Em termo equivalente, selecionamos um termo equivalente da nossa lista de termos em português ou inglês. No nosso caso, todos os termos terão termos equivalentes no outro idioma, como no exemplo o termo “ring” é equivalente a “anel”.
Figura 16 ICVotec - tela de busca para termo equivalente. 
Figura 17 ICVotec - tela de busca para termos remissivos. 
Em informações enciclopédicas inserimos um artigo que define o nosso termo, colocamos a definição, o nome do artigo, sua fonte e o link para acesso.
Figura 18 ICVotec - tela para inserção de definições enciclopédicas.
Por fim, inserimos o conceito final e a definição. O conceito final é o conjunto de conceitos que o termo possui. Para a definição foi escrito um parágrafo para definir o termo, utilizamos os traços distintivos para selecionar os conceitos mais importantes, podemos também utilizar a definição dicionarizada e a definição enciclopédica para nos ajudar, as informações menos importantes para definir o termo foram colocadas em uma nota logo abaixo da definição.
Figura 19 Tabela para inserção para construção da definição final.
4. Resultados
A partir deste trabalho e análise desse corpus identificamos os seguintes termos em inglês: elves, hobbits, ring, men e ents; E em português identificamos: elfos, hobbits, anel, homens e ents.
Figura 20 ICVotec - página inicial do usuário.
Na página inicial da plataforma ICVoTec basta selecionar a área “terminologia em ficção” e depois “O senhor dos anéis” e clicar em buscar para mostrar todos os termos cadastrados.
Figura 21 Todos os termos cadastrados visão do usuário.
Figura 22 termos definidos.
Figura 23 Termos definidos ents(PT) e ents(EN).
Figura 24 Termos definidos hobbits (PT) e hobbits(EN).
5. Considerações finais
Aprendi bastante durante o percurso dessa PCC, tive contato com áreas que não teria normalmente como a terminologia bilíngue e a terminografia, pude também explorar a obra de Tolkien de um jeito diferente. Espero continuar esse trabalho aumentando o corpus adicionando outros livros de Tolkien.
Houve alguns desafios durante a análise dos termos, o mais notável foi o termo “elves” pois o livro em inglês quase sempre se refere a coisas dos elfos como “elf-alguma coisa” (ex.: elf-fountains, elf-lords, elf-towers, etc…) que gerou um pouco de confusão, a mesma coisa não acontece no termo em português.








Comentários
Postar um comentário